
Advanced How To Tutorial

I've decided to post my process as I get many questions. This is very advanced stuff, but it included some tips the average user might want to apply to their process. Some of this is easier than it looks. So firstly, the AI generators often make mistakes. Many images have extra limbs or detached body parts. It is often easier to keep trying than to fix mistakes. About 2% of the images i generate are of a good enough quality to work with. Of all the others I cut and paste the bits i want to keep and frankenstein together a final result using Photoshop.The anime AI has far better understanding of anatomy and is great with dynamic poses. Where as the photo real AI has been largely trained on selfies and portraits, it struggles to do complex abstract actions like orgies. So I generate everything as a cartoon first and then use that as a reference image to help the photo real AI understand what I want.First I start by generating all the poses out separately. This isn't necessary but i do find it more efficient and gives me more control. Since I'm changing the backgrounds everything has to get cut out anyhow.




This can be a rabbit hole. I add in levels of detail gradually in 15% increments because if I try to leap all the way from my source image to photo real the computer will dramatically change the likeness. So I have to go in baby steps. I cut out the best pieces from my attempts and assemble a final result. taking the lips from one image and the eyes from another. Sometimes even painting out things I don't want and painting in the things I do want. For example, I often have to paint in the bridge of the nose since anime often don't draw noses.

The AI often hits a roadblock when translating cartoons to photo real images. It wants to lean towards higher quality cartoons before making the leap into photo real quality. So I find it helps to remove the contour lines. Not all of them, but at least half of them. That's enough to encourage the AI to make the leap. In this case I had to hand paint out the outlines using the healing brush in Photoshop.

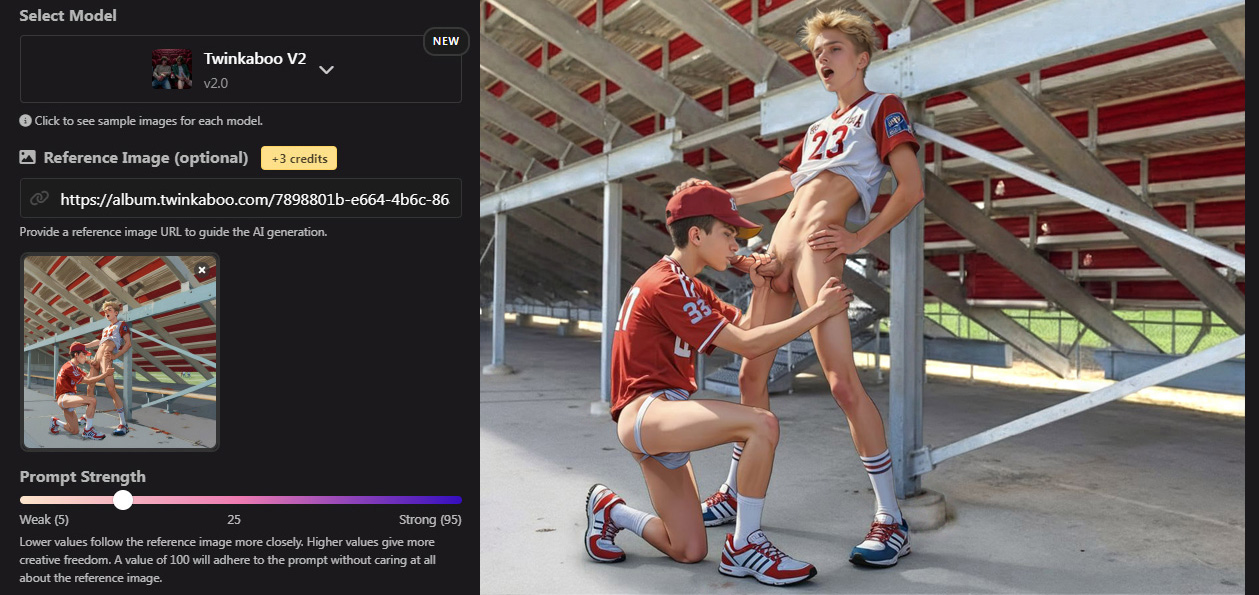
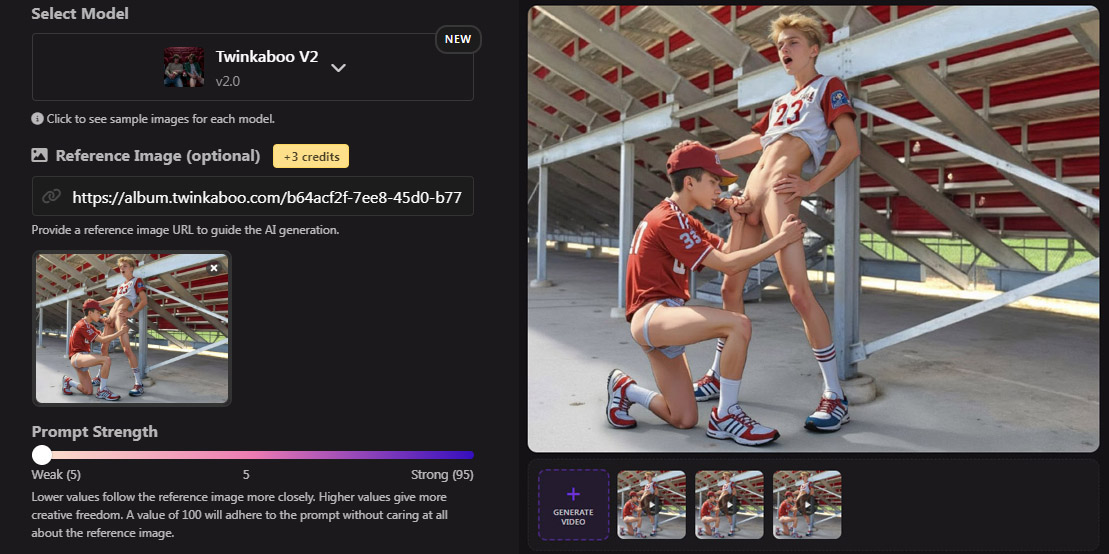
Check out my animated collections here:
https://twinkaboo.com/ai/collections/3ad79b02-8c86-44cf-aaa4-ebaab18ee4ab




Comments 1